
Semantic understanding of roadways is a key enabling factor for safe autonomous driving. However, existing autonomous driving datasets provide well-structured urban roads while ignoring unstructured roadways containing distress, potholes, water puddles, and various kinds of road patches i.e., earthen, gravel etc. To this end, we introduce \textbf{R}oad \textbf{R}egion \textbf{S}egmentation dataset (R\textsuperscript{2}S100K)---a large-scale dataset and benchmark for training and evaluation of road segmentation in aforementioned challenging {unstructured} roadways. R\textsuperscript{2}S100K comprises 100K images extracted from a large and diverse set of video sequences covering more than 1000 KM of roadways. Out of these 100K privacy respecting images, 14,000 images have fine pixel-labeling of road regions, with 86,000 unlabeled images that can be leveraged through semi-supervised learning methods. Alongside, we present an \textbf{E}fficient \textbf{D}ata \textbf{S}ampling (EDS) based self-training framework to improve learning by leveraging unlabeled data. Our experimental results demonstrate that the proposed method significantly improves learning methods in generalizability and reduces the labeling cost for semantic segmentation tasks. Our benchmark will be publicly available to facilitate future research at \url{https://github.com/r2s100k/data}.
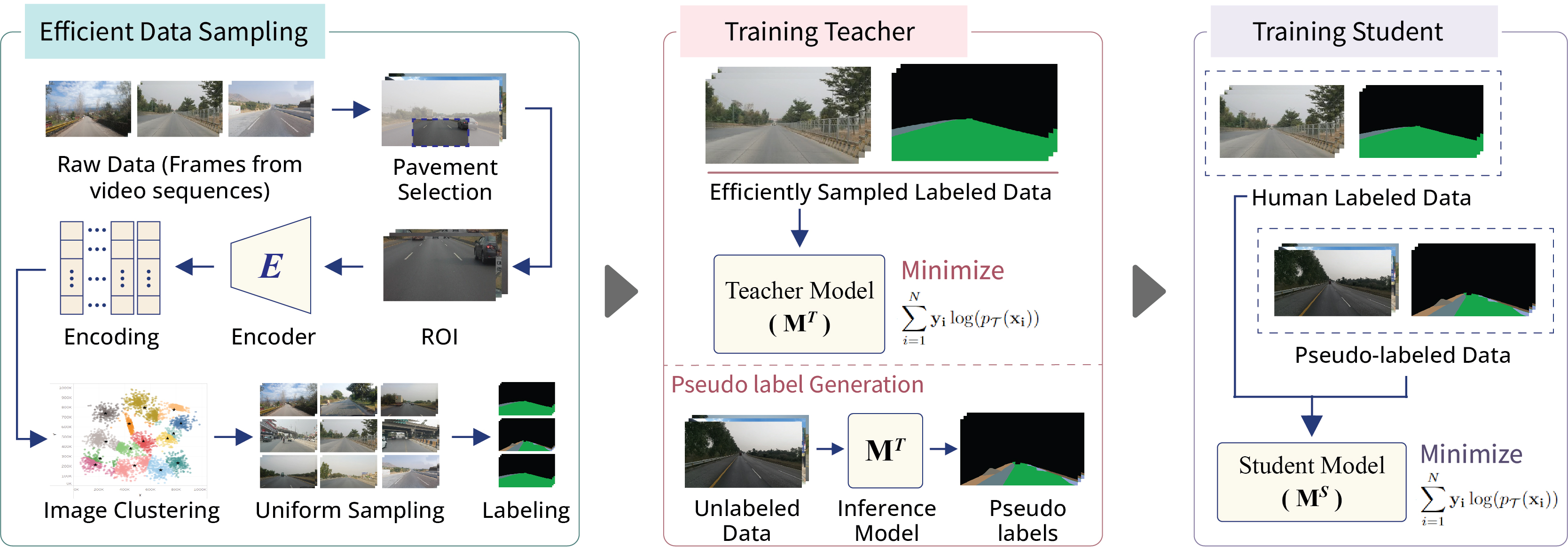
Firstly, raw data samples are clustered based on similarity in road classes among image encodings generated by an encoder. Then, a small subset is uniformly formed from all clusters for annotation to train teacher model. After training, pseudo-labels of unlabeled set are generated using teacher model, and student model is trained on real and pseudo labeled sets to achieve better generalization.

R2S100K covers more challenging/hazardous roads in both — the rural and rural areas. While, most of existing datasets focus on well-paved road infrastructure of urban areas, and do not distinguish among safe and hazardous road regions.
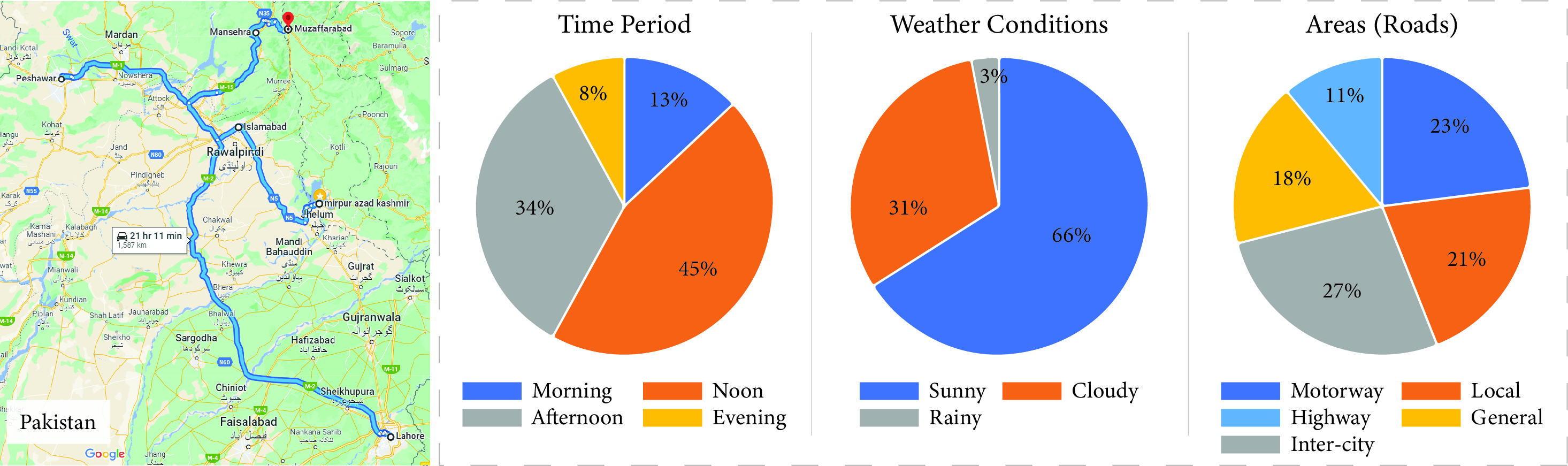
We cover over 1000 KMs of roadways of Pakistan—carefully considering the inclusion of motorways, highways, general inter-city and intra-city roads, as well as the rural and hilly areas, under different illuminous and weather conditions
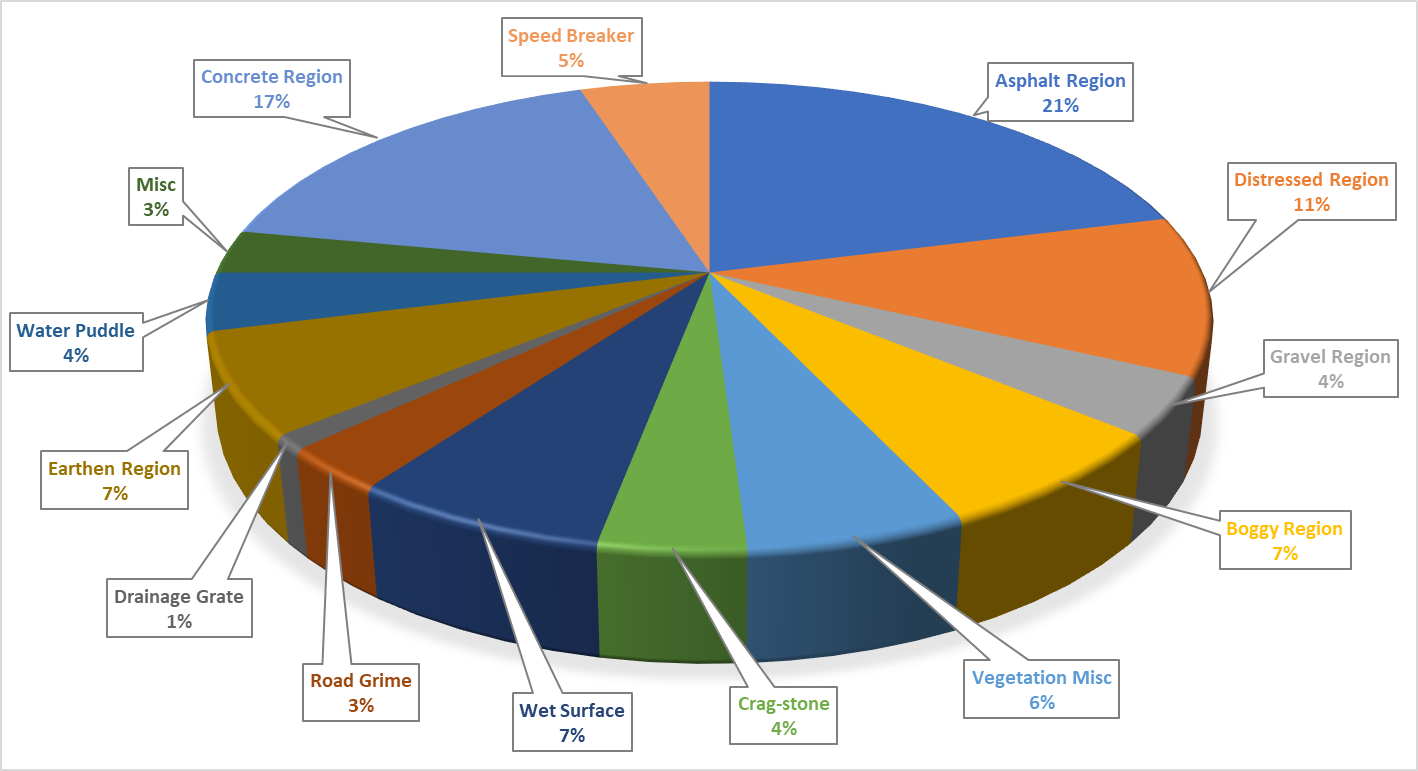
Asphalt and concrete regions represent the safe drivable road regions with the higher representation among the other hazardous road patches.
@article{atif2023r2s100k,
author = {Muhammad Atif Butt, Hassan Ali, Adnan Qayyum, Waqas Sultani, Ala Al-Fuqaha, and Junaid Qadir},
title = {R2S100K: Road-Region Segmentation Dataset For Semi-Supervised Autonomous Driving in the Wild},
journal = {arxiv},
year = {2023},
}